<문제>

이렇게 생긴 테이블을
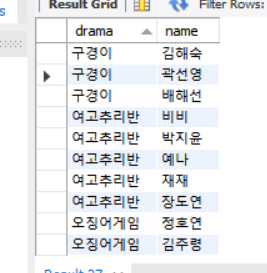
이렇게 바꾸는 방법!!
<모범 답안>
우선 모범 답안을 보고 코드를 뜯어보자.
select tb.drama,
substring_index(substring_index(tb.names, "$", numbers.n), "$" , -1) as name
from (
select 1 as n union all
select 2 union all
select 3 union all
select 4 union all
select 5) as numbers
inner join tb
on char_length(tb.names) - char_length(replace(tb.names, "$", "")) >= numbers.n - 1
order by tb.drama
<문제 풀이 과정>
어떻게 문자열을 쪼갤까?
| drama | names |
| 구경이 | 이영애$김혜준$김해숙$곽선영$배해선 |
| 여고추리반 | 비비$박지윤$예나$재재$장도연 |
| 오징어게임 | 정호연$김주령 |
주어진 tb라는 테이블이다. 우선 $기준으로 글자를 쪼갠다라는 아이디어에서 쉽게 substring_index() 를 연상시킬 수 있다.
참고로, substring_index(문자열, 구분자, 구분자 index) 이다.
예를들어 아래와 같이 사용한다.
select substring(names, "$", 1)
from tb
where drama = "구경이"> 이영애
select substring_index(names, "$", 2)
from tb
where drama = "구경이"> 이영애$김혜준
맨 앞글자가 아닌 문자열은 어떻게 추출할까?
그렇다면 이영애처럼 맨 앞글자일때는 구분자 index를 1로 설정하여 추출할 수 있지만, 김혜준은 어떻게 추출해야할까?
>이영애$김혜준 이라는 문자열에서 맨 뒤에 있는 글자를 선택하면 될 것이다.
그래서 우리는 substring_index 한 문자열에 한 번더 substring_index 함수를 먹여주는 것이다.
select substring_index(substring_index(names, "$", 2), "$", -1)
from tb
where drama = "구경이"> 김혜준
그렇다면 우리는
| 이영애$ |
| 이영애$김혜준 |
| 이영애$김혜준$김해숙 |
| 이영애$김혜준$김해숙$곽선영 |
| 이영애$김혜준$김해숙$곽선영$배해선 |
이라는 결과값을 얻어내서 맨 뒤에 있는 글자를 -1로 설정해서 추출해준다면 각 행에는 원하는 문자만 남길 수 있다.
각기 다른 구분자 index를 어떻게 처리할까?
그런데 또 문제가 있다.
저 결과값을 얻어내기 위해선 각기 다른 구분자 index를 설정해야 한다.
이영애$ 는 substring_index(substring_index(names, "$", 1)
이영애$김혜준 은 substring_index(substring_index(names, "$", 2)
이영애$김혜준$김해숙 은 substring_index(substring_index(names, "$", 3)
위에서 보는 것처럼, 각기 다른 숫자 index를 설정해야하기 때문에 단순 숫자를 넣는 것이 아닌 변수를 지정해야함을 알 수 있다.
| n |
| 1 |
| 2 |
| 3 |
n의 컬럼을 가진 number 라는 테이블이 있다고 해보자.
우린 number.n 이라는 칼럼을 이용해서 변수처럼 사용할 수 있다.
substring_index(names, "$", number.n) 이라고 해보자.
이 식은
substring_index(names, "$", 1)
substring_index(names, "$", 2)
substring_index(names, "$", 3)
위와 같은 과정을 다 포함하는 것이다.
그래서 우리는 1씩 증가하는 숫자들이 들어있는 임시테이블을 만든다.
select 1 as n union all
select 2 union all
select 3 union all
select 4 union all
select 5| n |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
위와 같은 결과를 얻을 수 있고, 해당 값을 조인해서 변수처럼 사용하기만 하면 된다.
중복되는 값 없이 문자열을 쪼개기 위해선 어떡할까?
select tb.drama,
substring_index(substring_index(tb.names, "$", numbers.n), "$" , -1) as name
from (
select 1 as n union all
select 2 union all
select 3 union all
select 4 union all
select 5) as numbers
inner join tb위 아이디어를 결합하면 해당 코드가 나온다.
그러나 예외를 생각해야할 점이 하나 있다.
여기서는 1부터 5까지만 있는 변수 테이블을 만들어서 상관은 없다.
그러나 1부터 8까지 있는 변수 테이블을 만들어서 조인한 결과를 봐보자.
| drama | name |
| 구경이 | 이영애 |
| 구경이 | 김혜준 |
| 구경이 | 김해숙 |
| 구경이 | 곽선영 |
| 구경이 | 배해선 |
| 구경이 | 배해선 |
| 구경이 | 배해선 |
| 구경이 | 배해선 |
배해선 배우가 4번이나 출연해주셨다..
왜그럴까?
다시 앞과정을 복기해보자.
substring_index(substring_index(tb.names, "$", 1), "$" , -1)
substring_index(substring_index(tb.names, "$", 2), "$" , -1)
substring_index(substring_index(tb.names, "$", 3), "$" , -1)
substring_index(substring_index(tb.names, "$", 4), "$" , -1)
substring_index(substring_index(tb.names, "$", 5), "$" , -1)
substring_index(substring_index(tb.names, "$", 6), "$" , -1)
substring_index(substring_index(tb.names, "$", 7), "$" , -1)
substring_index(substring_index(tb.names, "$", 8), "$" , -1)
이 과정을 다 문자열에 처리해서 나온 결과다.
이영애$김혜준$김해숙$곽선영$배해선
본래 주어진 위 문자열을 봐보면, $는 총 4개다.
가지고 있는 $의 개수를 넘는 수를 넣게된다면, 더이상 추출할 문자열이 없어 마지막 문자열이 나오는 것이다.
그래서, 배해선이 중복되어 나타났다는 걸 알 수 있다.
이를 수정하기 위해서 join 절에 조건이 들어가야 한다.
$개수 + 1 개만큼의 변수만 함수를 돌아가게 하면 올바른 결과를 얻을 수 있을 것이다.
$개수를 알아내기 위해서 char_length()를 이용한다.
이영애$김혜준$김해숙$곽선영$배해선 - 이영애김혜준김해숙곽선영배해선
= $$$$
가 되는 것처럼, 한쪽은 $를 제거하여 뺄셈을 한다면 쉽게 개수를 알아낼 수 있다.
CHAR_LENGTH VS LENGTH
둘 다 엄연히 글자의 길이를 재는 함수지만, LENGTH 함수는 BYTE 를 가져오기때문에, 한글은 정확한 길이를 알 수 없다.
CHAR_LENGTH 는 BYTE를 계산하지않고, 단순히 몇 개의 글자가 있는 지 세주는 함수
on char_length(tb.names) - char_length(replace(tb.names, "$", "")) >= numbers.n - 1해당 조건을 추가하면 올바른 결과를 얻을 수 있다.
참고 사이트 :
https://yamea-guide.tistory.com/88
'프로그래밍 언어 > SQL' 카테고리의 다른 글
| [Hackkerrank] The PADS (0) | 2022.01.25 |
|---|---|
| [HACKERRANK] AVERAGE POPULATION (0) | 2022.01.24 |
| [Hackerrank] Weather Observation Station 5 (0) | 2022.01.13 |
| [Hackerrank] Print Prime Numbers 풀이 (MySQL) (0) | 2022.01.13 |
| [프로그래머스 SQL 문제] 루시와 엘라 찾기 (0) | 2021.08.25 |
